@ישראל-מאיר-1 אנוכי הקטן, ניתן ליצור קשר במייל cs@abaye.co
א
מנותק
-
RE: מתכנת למערכת
-
RE: עזרה לפתיחת שלוחות
@EY.66969 תחפש את האקסס ליצירת שלוחות כאן בפורום,
אם אתה מעוניין בפיתרון מקצועי ונוח בתשלום תוכל לפנות אלי באישי
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
@S.I.Z אם זה זורק מיד זה כנראה לא בעיה בשאלון עצמו,
האם המערכת בשרת ymx (מערכת חדשה?)?
-
RE: בעיה ביצירת שלוחת API
@ARISH מה זה אומר לא ניתן לפתוח? מה אתה מנסה לעשות ומתי אתה מקבל שגיאה או מגיע למסקנה שלא ניתן לפתוח?
-
RE: מטופס Google לשאלון טלפוני - מילוי טופס מקוון של Google Forms דרך הטלפון
השאלה איך לא פיתחת עד היום כזה מודל בשביל כל המערכות שלך
לא אמרתי שלא פיתחתי
 רק כתבתי שזה עבודה להוסיף את זה לתוכנה הזו..
רק כתבתי שזה עבודה להוסיף את זה לתוכנה הזו.. -
RE: מטופס Google לשאלון טלפוני - מילוי טופס מקוון של Google Forms דרך הטלפון
@amram הזיהוי דיבור כעת הוא ברירת מחדל של ימות, שעולה יחידות, אתה יכול להשתמש בהקשות עם מקלדת עברית, אם יש צורך אני יכול להוסיף זיהוי דיבור מתקדם מחוץ לימות המשיח, אבל זה עבודה רצינית, אז אני לא אעשה את זה בלי שאדע שבאמת יש בזה צורך ללקוחות שמשלמים לי..
-
מטופס Google לשאלון טלפוני - מילוי טופס מקוון של Google Forms דרך הטלפון
אתמול רעננתי ושיפרתי מערכת ישנה שכתבתי בעבר שמאפשרת לשלוח תגובות לטופס Google Forms ציבורי מהמערכת הטלפונית, והעליתי אותה לכתובת חדשה. כעת היא זמינה גם במסלול חינמי.
אז מה המערכת עושה?
המערכת מאפשרת למי שמתקשר למערכת הטלפונית למלא טופס Google Forms באמצעות מקשי הטלפון בלבד (או זיהוי דיבור אם הגדרתם ויש לכם יחידות..).
במקום לפתוח את הטופס במחשב או בטלפון חכם, המתקשר שומע את שאלות הטופס, מקליד או מקליט את התשובות לפי הצורך, ובסיום כל הנתונים נשלחים אוטומטית אל Google Forms, בדיוק כאילו הטופס מולא דרך האתר.
המערכת מתאימה למגוון שימושים, לדוגמה:
- הרשמה לאירועים או פעילויות.
- מילוי סקרים ושאלונים.
- איסוף פרטי לקוחות.
- כל טופס אחר שנבנה ב-Google Forms.
המערכת קוראת את מבנה הטופס באופן אוטומטי, כך שאין צורך להגדיר כל שאלה בנפרד, אבל מאפשרת אחרי זה לערוך את הטקסטים של השאלות והתשובות, להתאים אותם למבנה הטלפוני, לעדכן את שיטת הקלט ולהוסיף הנחיות,
אפשר לנסות את המערכת כאן:
https://forms2call.dinobycloud.com -
RE: מילוי טופס מקוון של Google Forms דרך הקו
@חסיד-חזק יש כנראה תקלה גם במנוע הרגיל, בשאר השרתים יש קטיעות וקצת בעיות, אני התייאשתי מלפנות לימות המשיח, ביקשו ממני כבר 3 פעמים פרטי שיחה מאות יום, כל פעם נזכרים כמה ימים אחרי זה לבקש שוב, מישהו שם לא רציני, ולדעתי הם רק יפסידו מזה (ומשאר הדברים..) את הלקוחות העסקיים..
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
@חסיד-חזק המערכת של בשרת ymx?
נסה אם כן להגידר בivr.ini את הגדרות הקול הבאות
voice=ymMale tts_voice=ymMale rate=2 tts_rate=2 -
RE: מילוי טופס מקוון של Google Forms דרך הקו
@שמואל-ש. תודה על העדכון, סידרתי,
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
הלינק לאפליקציה החדשה/ישנה שלי, כעת ניתן להירשם ולהשתמש ללא צורך בפניה אלי, https://forms2call.dinobycloud.com
(שלחתי פניה לנטפרי)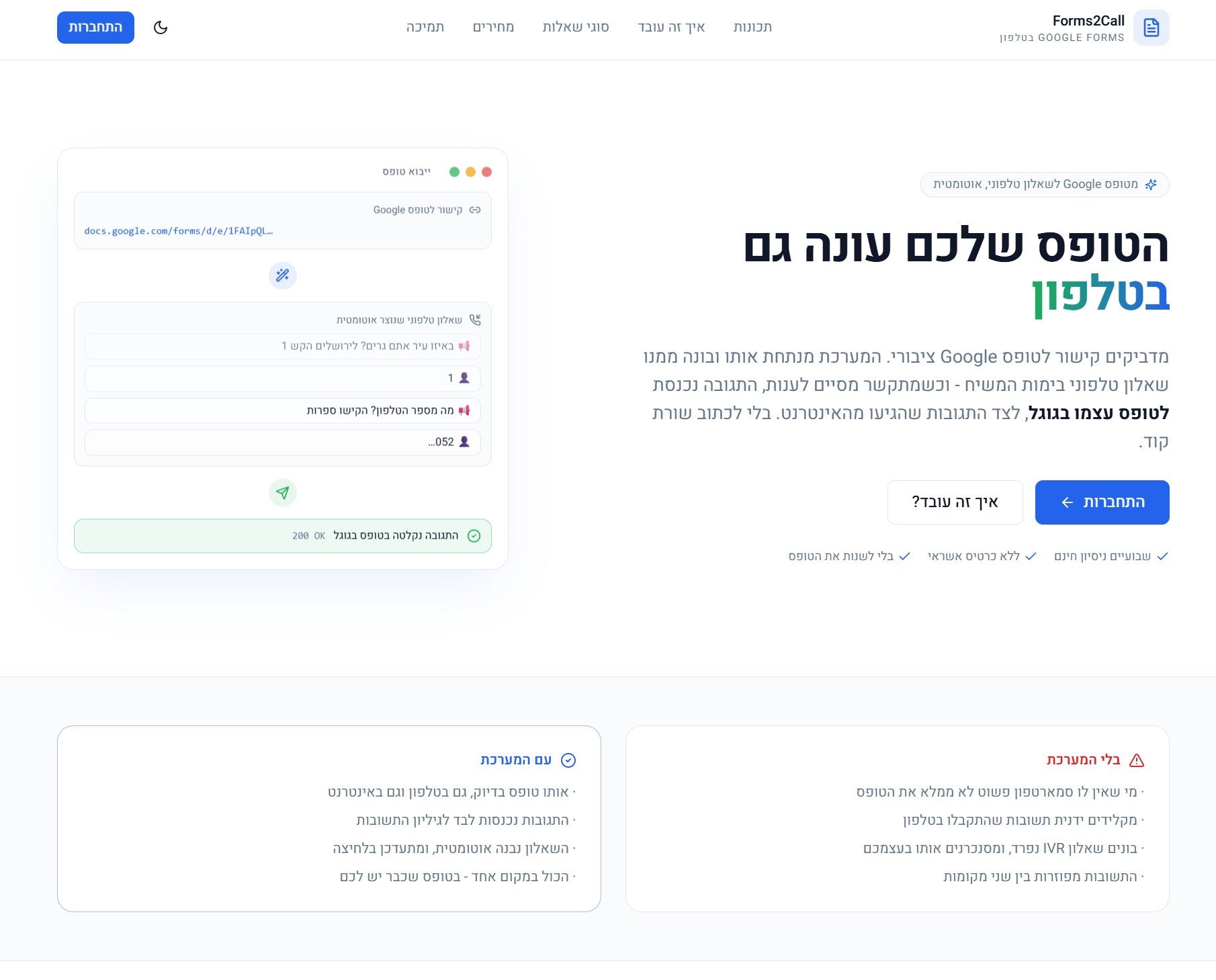
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
מכיון שאני רואה שיש לזה ביקוש קצת, אני אפרסם עוד מעט משהו שכתבתי לזה, שמאפשר להכניס כתובת של טופס בגוגל והתוכנה מנתחת אותו אוטומטית ומאפשרת לענות עליו מהטלפון ולשלוח תגובה מתוך הטופס עצמו
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
@חסיד-חזק יש לי משהו שיכול להתלבש על כל טופס ציבורי שלא דורש התחברות עם גוגל,
אם אתה מעוניין בפרטים, תוכל לפנות בפרטי כנ"ל
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
@מזוזת לטופס ספציפי או משהו שיתאים לכל טופס?
אתה יכול לפנות למייל cs@abaye.co
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
@מזוזת אם הנתונים יגיעו לשיטס המקושר לגוגל פרומס הם יתעדכנו כתושובות שענו???
לא צריך את זה, יש לגוגל פרומס ממשק API
-
RE: מילוי טופס מקוון של Google Forms דרך הקו
@מזוזת יש לי פיתוח כזה בתשלום, אם אתה מעוניין תוכל לפנות בפרטי