import pandas as pd
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
import os
import asyncio
import edge_tts
import subprocess
import json
import urllib.request
import zipfile
import shutil
import warnings
warnings.filterwarnings("ignore")
DEFAULT_TTS_VOICE = "he-IL-AvriNeural"
# נגדיר את FFMPEG_EXECUTABLE כ-None בהתחלה, ורק נאתחל אותו כשנצטרך
FFMPEG_EXECUTABLE = None
def read_excel_data(excel_file_path):
print(f"📖 קורא קובץ אקסל: {excel_file_path}")
try:
df = pd.read_excel(excel_file_path, header=None)
username = str(df.iloc[0, 1]).strip()
password = str(df.iloc[1, 1]).strip()
if not username:
print("❌ שגיאה: אנא הכנס מספר מערכת (תא B1 באקסל).")
return None, None, None
if not password:
print("❌ שגיאה: אנא הכנס סיסמא (תא B2 באקסל).")
return None, None, None
extensions = df.iloc[5:, [0, 1, 2, 3, 4]].dropna(how='all')
extensions.columns = ['נתיב', 'הגדרה', 'שם השלוחה', 'קובץ שמע להעלאה', 'קובץ טקסט להעלאה']
extensions = extensions.apply(lambda x: x.astype(str).str.strip().replace('nan', '') if x.dtype == 'object' else x)
print(f"✔️ נקראו בהצלחה: משתמש={username}, סיסמה={'*' * len(password)}")
print(f"📋 נתוני השלוחות שנקראו:\n{extensions.to_string()}")
return username, password, extensions.to_dict('records')
except FileNotFoundError:
print(f"❌ שגיאה: קובץ האקסל '{excel_file_path}' לא נמצא. ודא שהוא באותה תיקייה כמו הסקריפט.")
return None, None, None
except Exception as e:
print(f"❌ שגיאה בקריאת קובץ האקסל: {e}")
return None, None, None
def create_ext_ini_file(extension_type, extension_name, output_file_name, is_subpath=False, direct_ini_content=None):
content = ""
if direct_ini_content:
content = direct_ini_content.strip()
if not content.endswith('\n'):
content += '\n'
print(f"⚙️ יוצר קובץ ext.ini מתוכן INI ישיר.")
elif is_subpath:
content = "type=menu\n"
else:
normalized_extension_type = str(extension_type).strip().lower() if extension_type else ""
if pd.isna(extension_type):
normalized_extension_type = ""
if normalized_extension_type == 'השמעת קבצים':
content = "type=playfile\n"
elif normalized_extension_type == 'תפריט':
content = "type=menu\n"
elif normalized_extension_type in ['הקלטה', 'הקלטות']:
content = "type=record\n"
else:
print(f"⚠️ סוג שלוחה לא מוכר '{extension_type}'. מוגדר כ-'תפריט' כברירת מחדל.")
content = "type=menu\n"
if extension_name and extension_name.strip():
content += f"title={extension_name.strip()}\n"
try:
with open(output_file_name, 'w', encoding='utf-8') as f:
f.write(content)
print(f"✅ נוצר קובץ {output_file_name} עם תוכן: {content.strip() or '[ריק]'}")
return True
except Exception as e:
print(f"❌ שגיאה ביצירת קובץ {output_file_name}: {e}")
return False
async def create_and_convert_audio_file(text, output_wav_name):
output_mp3_temp = f"temp_{os.path.splitext(output_wav_name)[0]}.mp3"
print(f"🔊 יוצר קובץ שמע {output_wav_name} מטקסט: '{text}'")
# הבדיקה והאיתחול של FFMPEG_EXECUTABLE מתרחשים כאן בלבד
global FFMPEG_EXECUTABLE
if not FFMPEG_EXECUTABLE or not os.path.exists(FFMPEG_EXECUTABLE):
print(f"⏳ מנסה להוריד או לאתר את FFmpeg כיוון שנדרש לטיפול בקבצי שמע...")
ensure_ffmpeg() # קוראים ל-ensure_ffmpeg רק כאן
if not FFMPEG_EXECUTABLE or not os.path.exists(FFMPEG_EXECUTABLE):
print(f"❌ לא ניתן ליצור קובץ שמע {output_wav_name} כי FFmpeg לא זמין.")
return False
try:
comm = edge_tts.Communicate(text, voice=DEFAULT_TTS_VOICE)
await comm.save(output_mp3_temp)
print(f"✅ קובץ אודיו זמני נוצר בהצלחה: {output_mp3_temp}")
result = subprocess.run(
[FFMPEG_EXECUTABLE, "-loglevel", "error", "-y", "-i", output_mp3_temp, "-ar", "8000", "-ac", "1", "-acodec", "pcm_s16le", output_wav_name],
check=True
)
print(f"✅ קובץ WAV סופי נוצר בהצלחה: {output_wav_name}")
return True
except edge_tts.exceptions.NoAudioReceived as e:
print(f"❌ שגיאה ביצירת קובץ שמע {output_wav_name}: {e}")
print("❗ ודא/י חיבור אינטרנט תקין, אין חסימות חומת אש/אנטי-וירוס, או נסה/י קול אחר.")
except subprocess.CalledProcessError as e:
print(f"❌ שגיאה בהמרת אודיו (FFmpeg) עבור {output_wav_name}: {e}. ודא/י ש-FFmpeg מותקן ונגיש.")
except FileNotFoundError:
print(f"❌ שגיאה: FFmpeg לא נמצא בנתיב המוגדר. ודא/י שהורד והוגדר כראוי.")
except Exception as e:
print(f"❌ שגיאה כללית ביצירת/המרת אודיו עבור {output_wav_name}: {e}")
finally:
if os.path.exists(output_mp3_temp):
os.remove(output_mp3_temp)
return False
def create_text_file(text, output_file_name):
print(f"📝 יוצר קובץ טקסט {output_file_name} עם תוכן: {text}")
try:
with open(output_file_name, 'w', encoding='utf-8') as f:
f.write(text)
print(f"✅ קובץ טקסט {output_file_name} נוצר בהצלחה")
return True
except Exception as e:
print(f"❌ שגיאה ביצירת קובץ טקסט {output_file_name}: {e}")
return False
def upload_file_to_yemot(file_path, yemot_full_path, username, password):
token = f"{username}:{password}"
file_ext = file_path.lower()
if file_ext.endswith('.wav'):
content_type = 'audio/wav'
elif file_ext.endswith('.txt') or file_ext.endswith('.tts'):
content_type = 'text/plain'
elif file_ext.endswith('.ini'):
content_type = 'text/plain'
else:
content_type = 'application/octet-stream'
try:
with open(file_path, 'rb') as f_read:
m = MultipartEncoder(fields={
"token": token,
"path": yemot_full_path,
"upload": (os.path.basename(file_path), f_read, content_type)
})
print(f"⬆️ מעלה קובץ {os.path.basename(file_path)} לנתיב: {yemot_full_path}")
r = requests.post("https://www.call2all.co.il/ym/api/UploadFile", data=m, headers={'Content-Type': m.content_type})
r.raise_for_status()
print(f"✔️ הקובץ '{os.path.basename(file_path)}' הועלה בהצלחה")
return True
except FileNotFoundError:
print(f"❌ שגיאה: קובץ מקור להעלאה לא נמצא: {file_path}")
return False
except requests.exceptions.RequestException as e:
print(f"❌ שגיאה בהעלאת קובץ {os.path.basename(file_path)}: {e}")
print(f"📤 תגובת שרת: {r.text if 'r' in locals() else 'אין תגובה מהשרת'}")
return False
except Exception as e:
print(f"❌ שגיאה בלתי צפויה בהעלאת קובץ {os.path.basename(file_path)}: {e}")
return False
def generate_subpaths(full_path):
parts = [p for p in full_path.split('/') if p]
subpaths = []
current_path_parts = []
for part in parts[:-1]:
current_path_parts.append(part)
subpaths.append('/'.join(current_path_parts))
return subpaths
def test_yemot_credentials(username, password):
token = f"{username}:{password}"
dummy_file_name = "temp_cred_test.txt"
dummy_file_path_local = os.path.join(os.getcwd(), dummy_file_name)
yemot_target_path = "ivr2:/temp_credential_test_folder/test_file.txt"
try:
with open(dummy_file_path_local, "w") as f:
f.write("test_content")
print("⏳ בודק שם משתמש וסיסמא מול מערכת ימות המשיח...")
with open(dummy_file_path_local, 'rb') as f_read_dummy:
m = MultipartEncoder(fields={
"token": token,
"path": yemot_target_path,
"upload": (dummy_file_name, f_read_dummy, 'text/plain')
})
r = requests.post("https://www.call2all.co.il/ym/api/UploadFile", data=m, headers={'Content-Type': m.content_type})
response_text = r.text.strip()
response_text_upper = response_text.upper()
if r.status_code == 401 or r.status_code == 403:
print("❌ שם משתמש ו/או סיסמא לא תקין. שגיאת אימות (Unauthorized/Forbidden).")
return False
try:
response_json = json.loads(response_text)
if response_json.get("responseStatus") == "OK" and response_json.get("success") == True:
print("✅ שם משתמש וסיסמא תקינים.")
return True
elif "TOKEN INVALID" in response_text_upper or \
"המספר אינו מורשה" in response_text_upper or \
"THE NUMBER IS NOT VALID" in response_text_upper or \
"מספר המערכת אינו תקין" in response_text_upper:
print("❌ שם משתמש ו/או סיסמא לא תקין.")
return False
else:
print(f"❌ שם משתמש ו/או סיסמא לא תקין. תגובת שרת לא צפויה: {response_text}")
return False
except json.JSONDecodeError:
if "ERROR:" in response_text_upper:
if "TOKEN INVALID" in response_text_upper or \
"המספר אינו מורשה" in response_text_upper or \
"THE NUMBER IS NOT VALID" in response_text_upper or \
"מספר המערכת אינו תקין" in response_text_upper:
print("❌ שם משתמש ו/או סיסמא לא תקין.")
return False
else:
print(f"❌ שם משתמש ו/או סיסמא לא תקין. שגיאת שרת לא ספציפית: {response_text}")
return False
else:
print(f"❌ שם משתמש ו/או סיסמא לא תקין. תגובת שרת בפורמט לא צפוי: {response_text}")
return False
except requests.exceptions.RequestException as e:
print(f"❌ שגיאת חיבור או תקשורת בעת בדיקת התחברות: {e}")
print("❗ ודא/י חיבור אינטרנט תקין.")
return False
except Exception as e:
print(f"❌ שגיאה בלתי צפויה בעת בדיקת התחברות: {e}")
return False
finally:
if os.path.exists(dummy_file_path_local):
try:
os.remove(dummy_file_path_local)
except OSError as e:
print(f"⚠️ אזהרה: לא ניתן למחוק את קובץ הדמה '{dummy_file_path_local}': {e}")
def ensure_ffmpeg():
global FFMPEG_EXECUTABLE
local_ffmpeg_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "bin", "ffmpeg.exe")
if os.path.exists(local_ffmpeg_path):
print("⏩ ffmpeg כבר קיים בנתיב המקומי.")
FFMPEG_EXECUTABLE = local_ffmpeg_path
return
print("⬇️ מוריד ומגדיר ffmpeg...")
os.makedirs(os.path.dirname(local_ffmpeg_path), exist_ok=True)
url = "https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-essentials.zip"
archive_path = os.path.join(os.path.dirname(local_ffmpeg_path), "ffmpeg.zip")
try:
print(f"📥 מוריד קובץ FFmpeg מ: {url}")
urllib.request.urlretrieve(url, archive_path)
print(f"📦 חולץ את קובץ FFmpeg מ: {archive_path}")
with zipfile.ZipFile(archive_path, 'r') as zip_ref:
found_ffmpeg_in_zip = False
for member in zip_ref.namelist():
if member.endswith('ffmpeg.exe'):
source = zip_ref.open(member)
target = open(local_ffmpeg_path, "wb")
with source, target:
shutil.copyfileobj(source, target)
print(f"✅ FFmpeg הוכן בהצלחה ב: {local_ffmpeg_path}")
FFMPEG_EXECUTABLE = local_ffmpeg_path
found_ffmpeg_in_zip = True
break
if not found_ffmpeg_in_zip:
print("❌ שגיאה: לא נמצא ffmpeg.exe בתוך קובץ ה-ZIP שהורד.")
FFMPEG_EXECUTABLE = None
return
except Exception as e:
print(f"❌ שגיאה בהורדה או בחילוץ של FFmpeg: {e}")
print("❗ ודא/י חיבור אינטרנט תקין ונסה/י שוב.")
FFMPEG_EXECUTABLE = None
finally:
if os.path.exists(archive_path):
try:
os.remove(archive_path)
except OSError as e:
print(f"⚠️ אזהרה: לא ניתן למחוק את קובץ ה-ZIP הזמני '{archive_path}': {e}")
if not os.path.exists(local_ffmpeg_path):
print("❌ FFmpeg לא הותקן אוטומטית. אנא הורד/י והתקן/י אותו ידנית.")
print("ניתן להוריד מכאן: https://www.gyan.dev/ffmpeg/builds/ (בחר/י את גרסת Essentials או Full עבור Windows).")
FFMPEG_EXECUTABLE = None
async def main():
print("🚀 מתחיל תהליך יצירת והעלאת שלוחות...")
# ensure_ffmpeg() הוסר מכאן - יופעל רק במידת הצורך
# if not FFMPEG_EXECUTABLE or not os.path.exists(FFMPEG_EXECUTABLE):
# print("⚠️ התהליך נעצר עקב חוסר ב-FFmpeg. אנא התקן/י אותו ידנית כדי להמשיך.")
# return
script_dir = os.path.dirname(os.path.abspath(__file__))
excel_file = os.path.join(script_dir, "משני.xlsx")
print(f"📂 תיקיית הסקריפט: {script_dir}")
print(f"🔍 מחפש קובץ אקסל: {excel_file}")
if not os.path.exists(excel_file):
print(f"❌ קובץ האקסל '{excel_file}' לא נמצא בתיקיית הסקריפט!")
print(f"📋 קבצים בתיקייה: {os.listdir(script_dir)}")
return
username, password, extensions_data = read_excel_data(excel_file)
if not username or not password or not extensions_data:
print("⚠️ התהליך נעצר עקב חוסר בנתוני התחברות או נתוני שלוחות.")
return
if not test_yemot_credentials(username, password):
print("⚠️ התהליך נעצר עקב פרטי התחברות לא תקינים.")
return
processed_subfolders = set()
for ext in extensions_data:
path = ext.get('נתיב')
extension_type = ext.get('הגדרה')
extension_name = ext.get('שם השלוחה')
audio_content = ext.get('קובץ שמע להעלאה', '')
text_content = ext.get('קובץ טקסט להעלאה', '')
if isinstance(path, str): path = path.strip()
if isinstance(extension_type, str): extension_type = extension_type.strip()
if isinstance(extension_name, str): extension_name = extension_name.strip()
if isinstance(audio_content, str): audio_content = audio_content.strip().replace('...', '')
if isinstance(text_content, str): text_content = text_content.strip().replace('...', '')
if not path:
print(f"⚠️ דילוג על שלוחה: נתיב לא תקין או חסר '{path}'")
continue
clean_path = path
print(f"\n📋 מעבד שלוחה: {extension_name} ({path})")
subpaths_to_create = generate_subpaths(clean_path)
for subpath_item in subpaths_to_create:
full_sub_yemot_ini_path = f"ivr2:/{subpath_item}/ext.ini"
if full_sub_yemot_ini_path not in processed_subfolders:
print(f"⚙️ מעבד תת-שלוחה (ברירת מחדל menu): {full_sub_yemot_ini_path}")
ini_file_name = "ext.ini"
if create_ext_ini_file(None, None, ini_file_name, is_subpath=True):
if not upload_file_to_yemot(ini_file_name, full_sub_yemot_ini_path, username, password):
print(f"❌ שגיאה בהעלאת INI לתת-שלוחה {full_sub_yemot_ini_path}. המשך עיבוד...")
else:
print(f"❌ שגיאה ביצירת INI לתת-שלוחה {full_sub_yemot_ini_path}. מדלג.")
if os.path.exists(ini_file_name):
os.remove(ini_file_name)
processed_subfolders.add(full_sub_yemot_ini_path)
main_ini_file = "ext.ini"
target_yemot_ini_path = f"ivr2:/{clean_path}/ext.ini"
should_create_main_ext_ini = True
is_direct_ini_input = False
ini_content_for_direct_upload = ""
if isinstance(extension_type, str) and extension_type.strip():
if ("type=" in extension_type.strip().lower() and "=" in extension_type.strip()) or "\n" in extension_type.strip():
is_direct_ini_input = True
ini_content_for_direct_upload = extension_type.strip()
if is_direct_ini_input:
if not create_ext_ini_file(None, None, main_ini_file, direct_ini_content=ini_content_for_direct_upload):
print(f"❌ שגיאה ביצירת INI ראשי מתוכן ישיר עבור {extension_name}. מדלג על שלוחה זו.")
continue
else:
normalized_ext_type_for_check = str(extension_type).strip().lower() if extension_type else ""
if pd.isna(extension_type):
normalized_ext_type_for_check = ""
if normalized_ext_type_for_check == 'תיקייה' or not normalized_ext_type_for_check:
print(f"🗂️ שלוחה מסוג '{normalized_ext_type_for_check or 'ריק'}'. לא נוצר קובץ ext.ini ראשי.")
should_create_main_ext_ini = False
else:
if not create_ext_ini_file(extension_type, extension_name, main_ini_file):
print(f"❌ שגיאה ביצירת INI ראשי עבור {extension_name}. מדלג על שלוחה זו.")
continue
if should_create_main_ext_ini:
if not upload_file_to_yemot(main_ini_file, target_yemot_ini_path, username, password):
print(f"❌ שגיאה בהעלאת INI ראשי עבור {extension_name}. המשך עיבוד...")
if os.path.exists(main_ini_file):
os.remove(main_ini_file)
continue
if os.path.exists(main_ini_file):
os.remove(main_ini_file)
# השינוי העיקרי: בדיקת audio_content לפני ניסיון יצירת קובץ שמע
if audio_content and audio_content.strip():
audio_texts = [t.strip() for t in audio_content.split(' + ') if t.strip()]
for i, text_to_tts in enumerate(audio_texts):
audio_wav_final = f"{str(i).zfill(3)}.wav"
# קריאה ל-create_and_convert_audio_file תטפל באיתחול FFmpeg אם נדרש
if await create_and_convert_audio_file(text_to_tts, audio_wav_final):
audio_yemot_path = f"ivr2:/{clean_path}/{audio_wav_final}"
upload_file_to_yemot(audio_wav_final, audio_yemot_path, username, password)
else:
print(f"⚠️ דילוג על העלאת קובץ שמע {audio_wav_final} עקב שגיאה ביצירה/המרה.")
if os.path.exists(audio_wav_final):
os.remove(audio_wav_final)
# קבצי טקסט אינם דורשים את FFmpeg, אז הם ממשיכים לפעול כרגיל
if text_content and text_content.strip() and (extension_type and pd.notna(extension_type)):
text_files_list = [t.strip() for t in text_content.split(' + ') if t.strip()]
for i, item_text_content in enumerate(text_files_list):
if os.path.exists(item_text_content):
file_name_to_upload = os.path.basename(item_text_content)
print(f"📄 מעלה קובץ טקסט קיים: {file_name_to_upload}")
text_yemot_path = f"ivr2:/{clean_path}/{file_name_to_upload}"
upload_file_to_yemot(item_text_content, text_yemot_path, username, password)
else:
text_file_name_final = f"{str(i).zfill(3)}.tts"
if create_text_file(item_text_content, text_file_name_final):
text_yemot_path = f"ivr2:/{clean_path}/{text_file_name_final}"
upload_file_to_yemot(text_file_name_final, text_yemot_path, username, password)
else:
print(f"⚠️ דילוג על העלאת קובץ טקסט {text_file_name_final} עקב שגיאה ביצירה.")
if os.path.exists(text_file_name_final):
os.remove(text_file_name_final)
print("\n✅ סיום עיבוד כל השלוחות בהצלחה!")
if __name__ == "__main__":
asyncio.run(main())



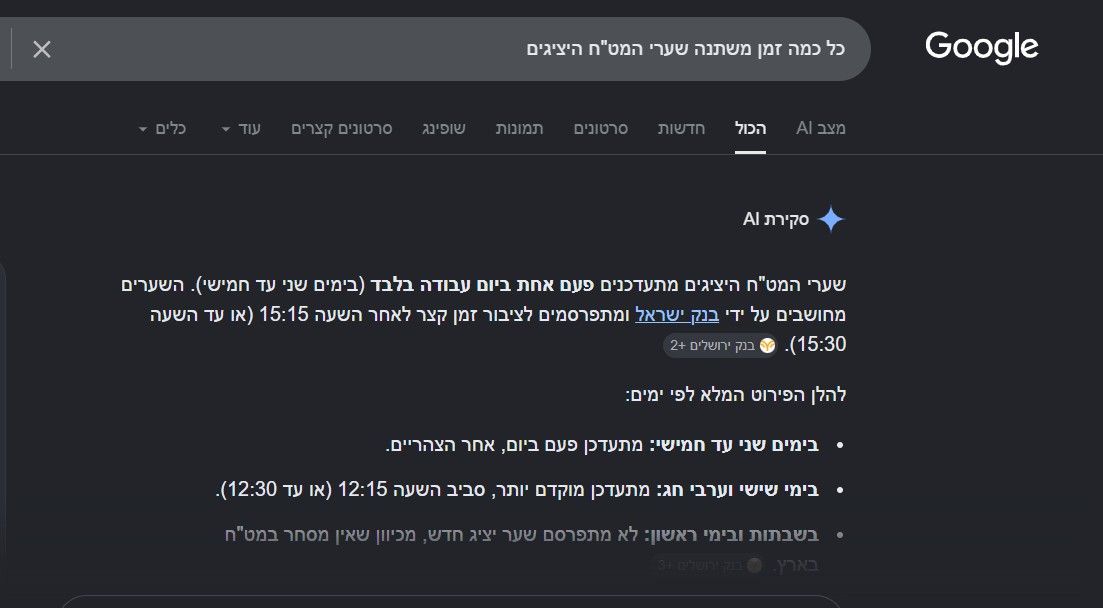
 ) והוא מעבד מידע! מבצע פעולות! מחזיר תשובות! וכו'
) והוא מעבד מידע! מבצע פעולות! מחזיר תשובות! וכו'
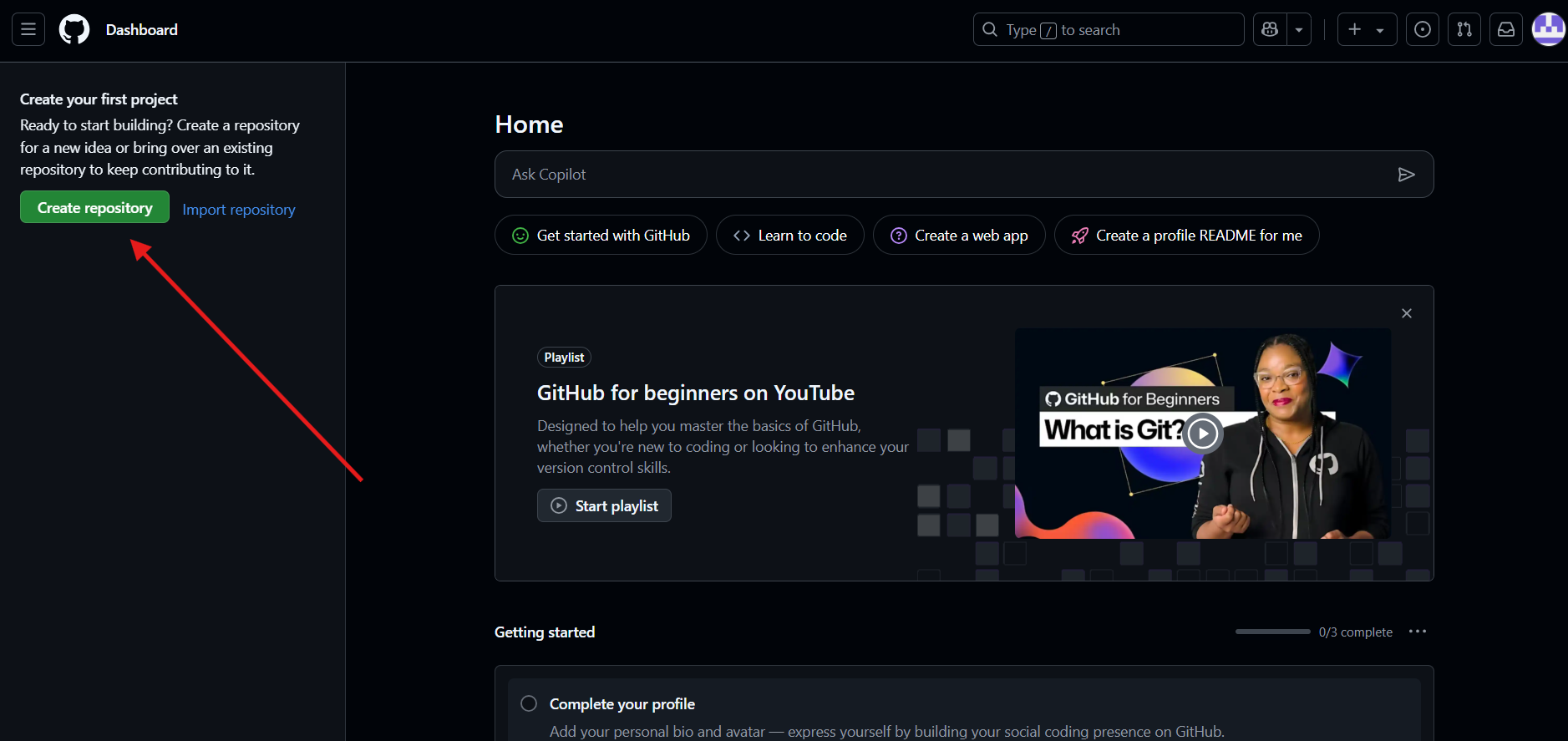
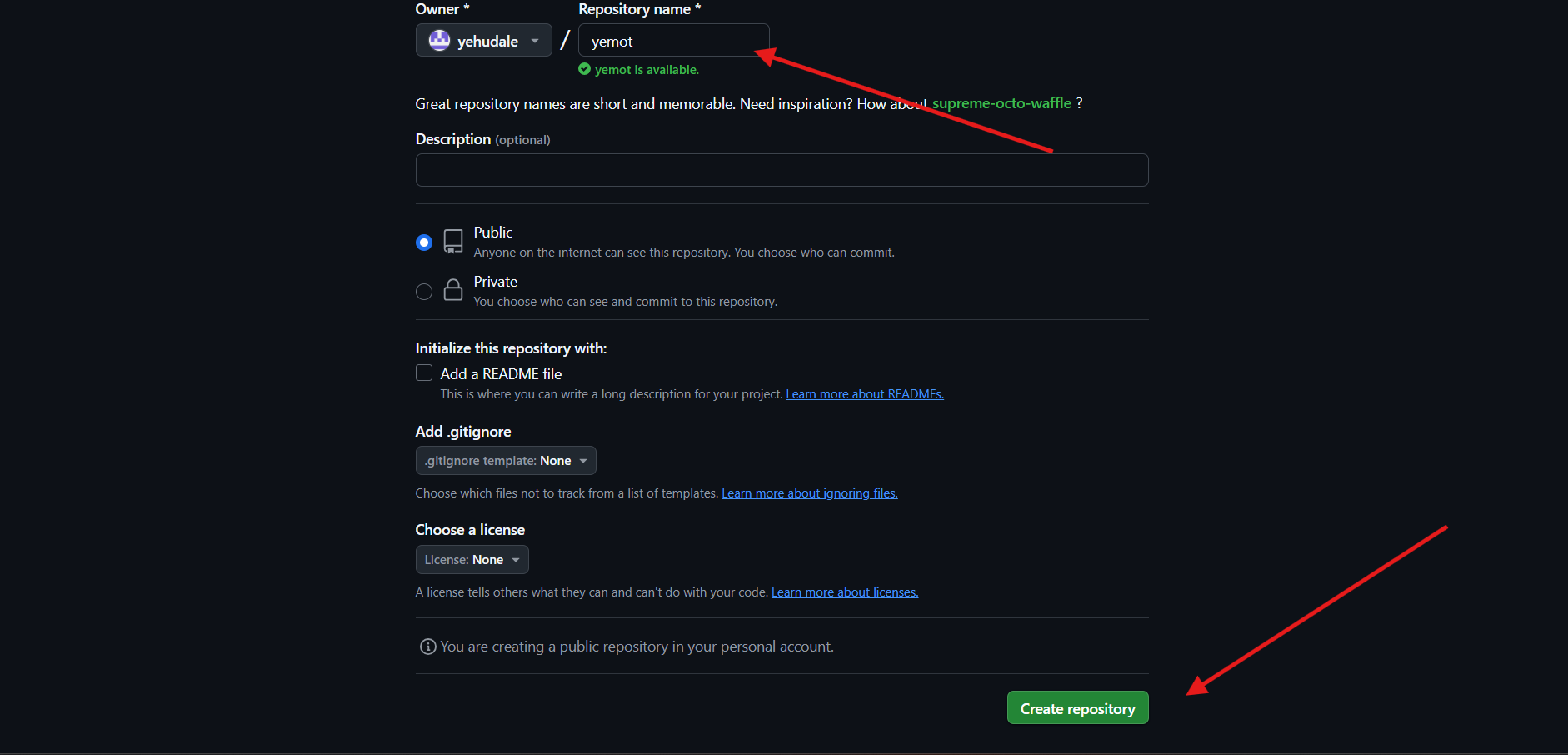
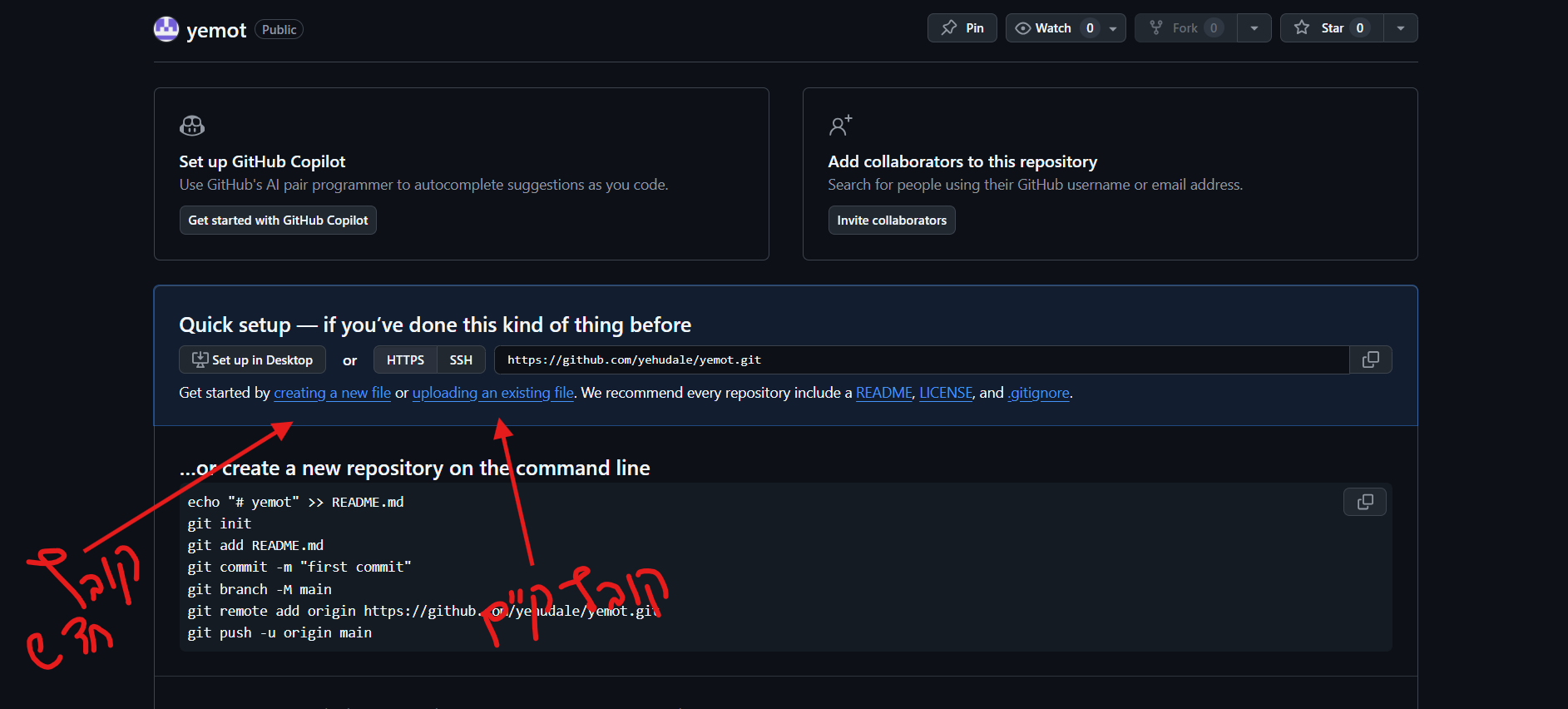
 הקישור לאתר:
הקישור לאתר:
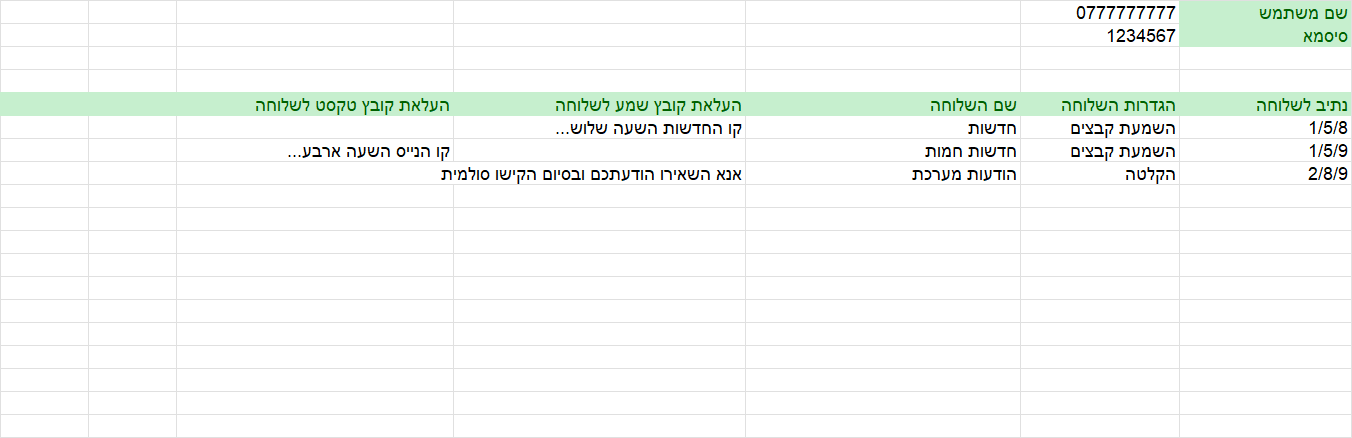
 )
)